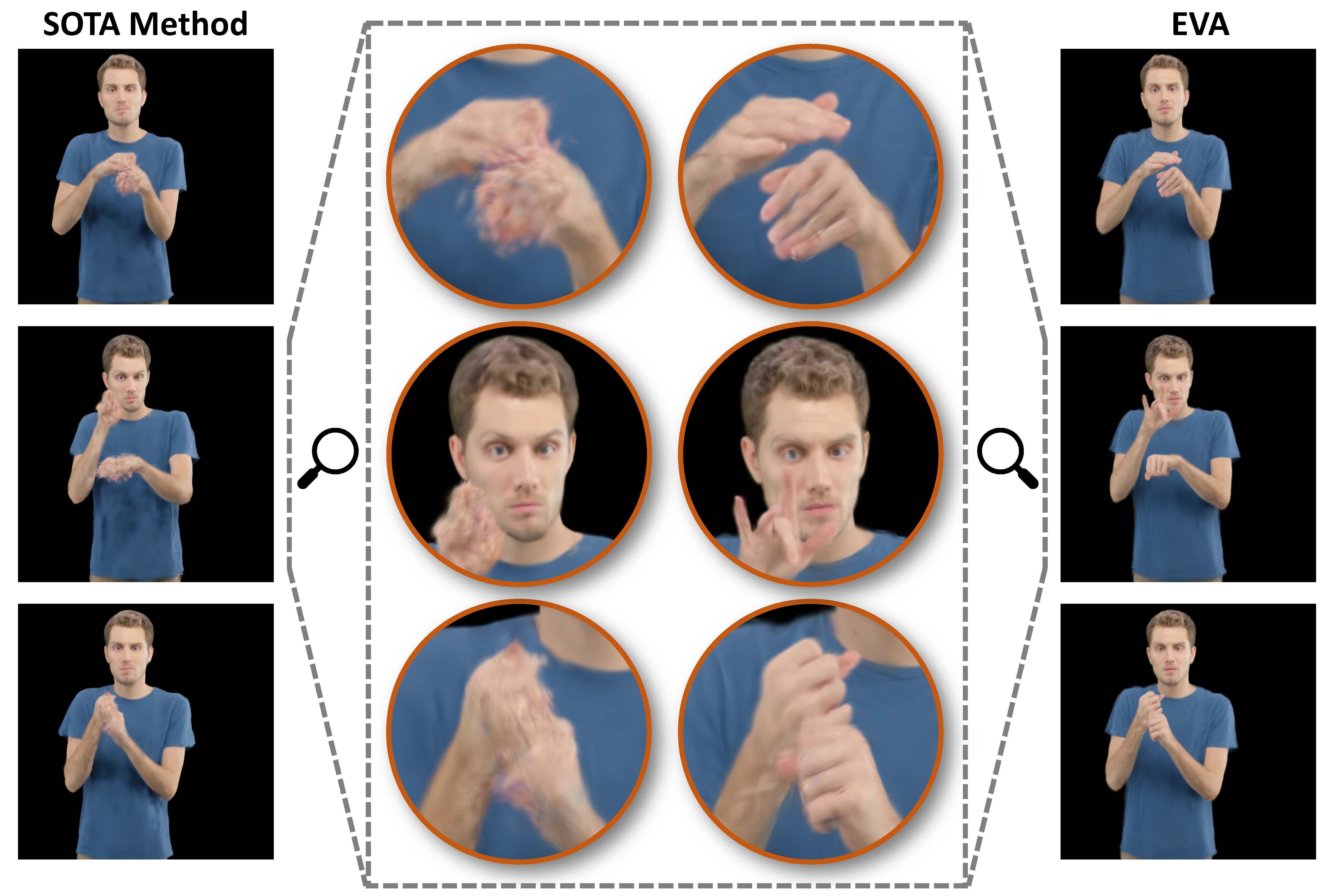
Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations.
In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details.
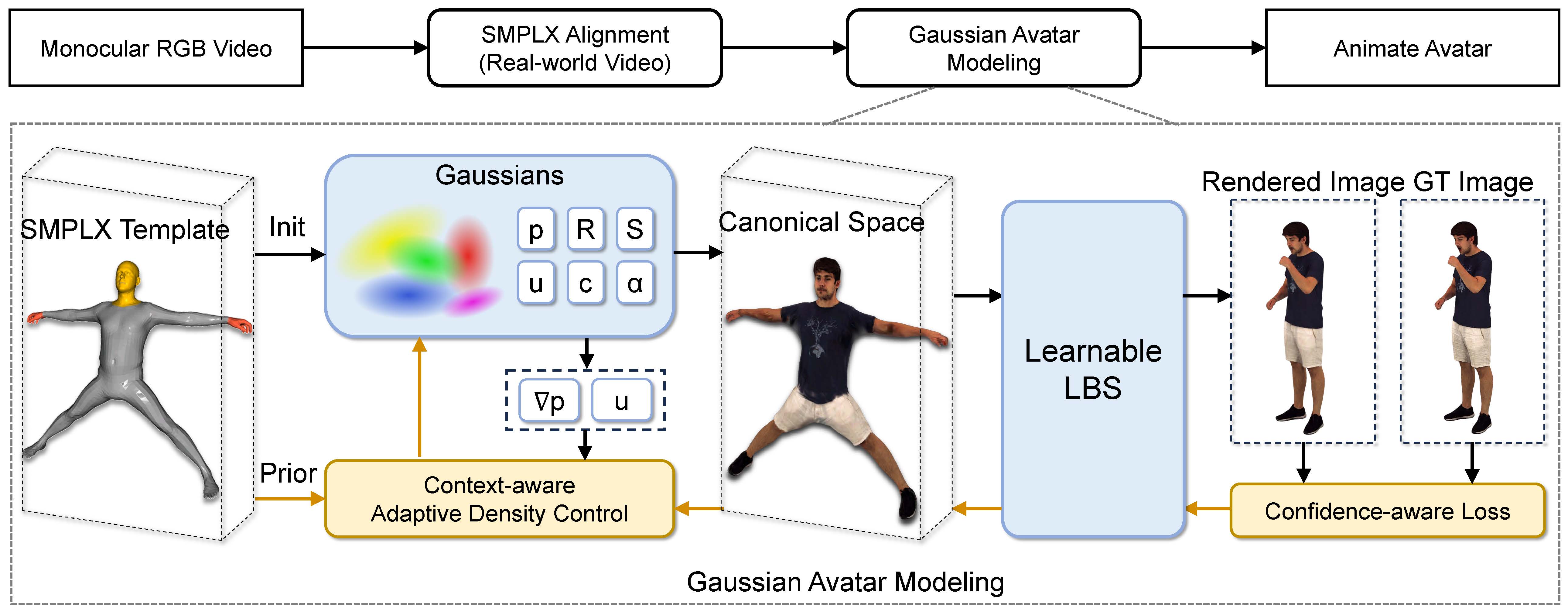
To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model.
Focused on enhancing expressiveness, our work makes three key contributions.
First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning.
Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues.
Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts.
Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians.
Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details.